Google published Zanzibar: Google’s Consistent, Global Authorization System in 2019. It describes a system for authorization – enforcing who can do what – which maxes out both flexibility and scalability. Google has lots of different apps that rely on Zanzibar, and bigger scale than practically any other company, so it needed Zanzibar.
The Zanzibar paper made quite a stir. There are at least four companies that advertise products as being inspired by or based on Zanzibar. It says a lot for everyone to loudly reference this paper on homepages and marketing materials: companies aren’t advertising their own innovation as much as simply saying they’re following the gospel.
I read the paper, and have a few notes, but the Google Zanzibar Paper, annotated by AuthZed is the same thing from a real domain expert (albeit one who works for one of these companies), so read that too, or instead.
Features
My brief summary is that the Zanzibar paper describes the features of the system succinctly, and those features are really appealing. They’ve figured out a few primitives from which developers can build really flexible authorization rules for almost any kind of application. They avoid making assumptions about ID formats, or any particular relations, or how groups are set up. It’s abstract and beautiful.
The gist of the system is:
Objects: things in your data model, like documents
Users: needs no explanation
Namespaces: for isolating applications
Usersets: groups of users
Userset rewrite rules: allow usersets to inherit from each other or have other kinds of set relationships
Tuples, which are like (object)#(relation)@(user), and are sort of the core ‘rule’ construct for saying who can access what
There’s then a neat configuration language which looks like this in an example:
It’s pretty neat. At this point in the paper I was sold on Zanzibar: I could see this as being a much nicer way to represent authorization than burying it in a bunch of queries.
Specifications & Implementation details
And then the paper discusses specifications: how much scale it can handle, and how it manages consistency. This is where it becomes much more noticeably Googley.
So, with Google’s scale and international footprint, all of their services need to be globally distributed. So Zanzibar is a distributed system, and it is also a system that needs good consistency guarantees so that it avoid the “new enemy” problem, nobody is able to access resources that they shouldn’t, and applications that are relying on Zanzibar can get a consistent view of its data.
Pages 5-11 are about this challenge, and it is a big one with a complex, high-end solution, and a lot of details that are very specific to Google. Most noticeably, Zanzibar is built with Spanner Google’s distributed database, and Spanner has the ability to order timestamps using TrueTime, which relies on atomic clocks and GPS antennae: this is not standard equipment for a server. Even CockroachDB, which is explicitly modeled off of Spanner, can’t rely on having GPS & atomic clocks around so it has to take a very different approach. But this time accuracy idea is pretty central to Zanzibar’s idea of zookies, which are sort of like tokens that get sent around in its API and indicate what time reference the client expects so that a follow-up response doesn’t accidentally include stale data.
To achieve scalability, Zanzibar is also a multi-server architecture: there are aclservers, watchservers, a Leopard indexing system that creates compressed skip list-based representations of usersets. There’s also a clever solution to the caching & hot-spot problem, in which certain objects or tuples will get lots of requests all at once so their database shard gets overwhelmed.
Conclusions
Zanzibar is two things:
A flexible, relationship-based access control model
A system to provide that model to applications at enormous scale and with consistency guarantees
My impressions of these things match with AuthZed’s writeup so I’ll just quote & link them:
There seems to be a lot of confusion about Zanzibar. Some people think all relationship-based access control is “Zanzibar”. This section really brings to light that the ReBAC concepts have already been explored in depth, and that Zanzibar is really the scaling achievement of bringing those concepts to Google’s scale needs. link
And
Zookies are very clearly important to Google. They get a significant amount of attention in the paper and are called out as a critical component in the conclusion. Why then do so many of the Zanzibar-like solutions that are cropping up give them essentially no thought? link
I finished the paper having absorbed a lot of tricky ideas about how to solve the distributed-consistency problems, and if I were to describe Zanzibar, those would be a big part of the story. But maybe that’s not what people mean when they say Zanzibar, and it’s more a description of features?
For my own needs, zookies and distributed consistency to the degree described in the Zanzibar paper are overkill. There’s no way that we’d deploy a sharded five-server system for authorization when the main application is doing just fine with single-instance Postgres. I want the API surface that Zanzibar describes, but would trade some scalability for simplicity. Or use a third-party service for authorization. Ideally, I wish there was something like these products but smaller, or delivered as a library rather than a server.
This week, Heroku made Router 2.0 generally available, bringing features like HTTP/2, performance improvements and reliability enhancements out of the beta program!
Throughout the Router 2.0 beta, our engineering team has addressed several bugs, all fairly straight-forward with one exception involving Puma-based applications. A small subset of Puma applications would experience increased response times upon enabling the Router 2.0 flag, reflected in customers’ Heroku dashboards and router logs. After thorough router investigation and peeling back Puma’s server code, we realized what we had stumbled upon was not actually a Router 2.0 performance issue. The root cause was a bug in Puma! This blog takes a deep dive into that investigation, including some tips for avoiding the bug on the Heroku platform while a fix in Puma is being developed. If you’d like a shorter ride (aka. the TL;DR), skip to The Solution section of this blog. For the full story and all the technical nitty gritty, read on.
The long response times issue first surfaced through a customer support ticket for an application running a Puma + Rails web server. As the customer reported, in high load scenarios, the performance differences between Router 2.0 and the legacy router were disturbingly stark. An application scaled to 2 Standard-1X dynos would handle 30 requests per second just fine through the legacy router. Through Router 2.0, the same traffic would produce very long tail response times (95th and 99th percentiles). Under enough load, throughput would drop and requests would fail with H12: Request Timeout. The impact was immediate upon enabling the http-routing-2-dot-0 feature flag:
At first, our team of engineers had difficulty reproducing the above, despite running a similarly configured Puma + Rails app on the same framework and language versions. We consistently saw good response times from our app.
Then we tried varying the Rails application’s internal response time. We injected some artificial server lag of 200 milliseconds and that’s when things really took off:
This was quite the realization! In staging environments, Router 2.0 is subject to automatic load tests that run continuously, at varied request rates, body sizes, protocol versions. etc.. These request rates routinely reach much higher levels than 30 requests per second. However, the target applications of these load tests did not include a Heroku app running Puma + Rails with any significant server-side lag.
With a reproduction in-hand, we were now in a position to investigate the high response times. We spun up our test app in a staging environment and started injecting a steady load of 30 requests per second.
Our first thought was that perhaps the legacy router is faster at forwarding requests to the dyno because its underlying TCP client manages connections in a way that plays nicer with the Puma server. We hopped on a router instance and began dumping netstat connection states for one of our Puma app's web dynos :
In the legacy router case, it seemed like there were fewer connections sitting in TIME_WAIT. This TCP state is a normal stop point along the lifecycle of a connection. It means the remote host (dyno) has sent a FIN indicating the connection should be closed. The local host (router) has sent back an ACK, acknowledging the connection is closed.
The connection hangs out for some time in TIME_WAIT, with the value varying among operating systems. The Linux default is 2 minutes. Once that timeout is hit, the socket is reclaimed and the router is free to re-use the address + port combination for a new connection.
With this understanding, we formed a hypothesis that the Router 2.0 HTTP client was churning through connections really quickly. Perhaps the new router was opening connections and forwarding requests at a faster rate than the legacy router, thus overwhelming the dyno.
Router 2.0 is written in Go and relies upon the language’s standard HTTP package. Some research turned up various tips for configuring Go’s http.Transport to avoid connection churn. The main recommendation involved tuning MaxIdleConnsPerHost . Without explicitly setting this configuration, the default value of 2 is used.
type Transport struct {
// MaxIdleConnsPerHost, if non-zero, controls the maximum idle
// (keep-alive) connections to keep per-host. If zero,
// DefaultMaxIdleConnsPerHost is used.
MaxIdleConnsPerHost int
...
}
const DefaultMaxIdleConnsPerHost = 2
The problem with a low cap on idle connections per host is that it forces Go to close connections more often. For example, if this value is set to a higher value, like 10, our HTTP transport will keep up to 10 idle connections for this dyno in the pool. Only when the 11th connection goes idle does the transport start closing connections. With the number limited to 2, the transport will close more connections which also means opening more connections to our dyno. This could put strain on the dyno as it requires Puma to spend more time handling connections and less time answering requests.
We wanted to test our hypothesis, so we set DefaultMaxIdleConnsPerHost: 100 on the Router 2.0 transport in staging. The connection distribution did change and now Router 2.0 connections were more stable than before:
root@router.1020195 | # netstat | grep 'ip-10-1-2-62.ec2.:37183'
tcp 0 0 ip-10-1-34-185.ec:36350 ip-10-1-2-62.ec2.:37183 ESTABLISHED
tcp 0 0 ip-10-1-34-185.ec:11956 ip-10-1-2-62.ec2.:37183 ESTABLISHED
tcp 0 0 ip-10-1-34-185.ec:51088 ip-10-1-2-62.ec2.:37183 ESTABLISHED
tcp 0 0 ip-10-1-34-185.ec:60876 ip-10-1-2-62.ec2.:37183 ESTABLISHED
To our dismay, this had zero positive effect on our tail response times. We were still seeing the 99th percentile at well over 2 seconds for a Rails endpoint that should only take about 200 milliseconds to respond.
We tried changing some other configurations on the Go HTTP transport, but saw no improvement. After several rounds of updating a config, waiting for the router artifact to build, and then waiting for the deployment to our staging environment, we began to wonder—can we reproduce this issue locally?
Fortunately, we already had a local integration test set-up for running requests through Router 2.0 to a dyno. We typically utilize this set-up for verifying features and fixes, rarely for assessing performance. We subbed out our locally running “dyno” for a Puma server with a built-in 200ms lag on the /fixed endpoint. We then fired off 200 requests over 10 different connections with hey:
As you can see, the 95th percentile of response times is over 2 seconds, just as we had seen while running this experiment on the platform. We were now starting to worry that the router itself was inflating the response times. We tried targeting Puma directly at localhost:3000, bypassing the router altogether:
Wow! These results suggested the issue is reproducible with any ‘ole Go HTTP client and a Puma server. We next wanted to test out a different client. The load injection tool, hey is also written in Go, just like Router 2.0. We next tried ab which is written in C:
❯ ab -c 10 -n 200 http://127.0.0.1:3000/fixed
This is ApacheBench, Version 2.3 <$Revision: 1913912 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 100 requests
Completed 200 requests
Finished 200 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 3000
Document Path: /fixed
Document Length: 3 bytes
Concurrency Level: 10
Time taken for tests: 8.538 seconds
Complete requests: 200
Failed requests: 0
Total transferred: 35000 bytes
HTML transferred: 600 bytes
Requests per second: 23.42 [#/sec] (mean)
Time per request: 426.911 [ms] (mean)
Time per request: 42.691 [ms] (mean, across all concurrent requests)
Transfer rate: 4.00 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 2
Processing: 204 409 34.6 415 434
Waiting: 204 409 34.7 415 434
Total: 205 410 34.5 415 435
Percentage of the requests served within a certain time (ms)
50% 415
66% 416
75% 416
80% 417
90% 417
95% 418
98% 420
99% 429
100% 435 (longest request)
Another wow! The longest request took about 400 milliseconds, much lower than the 2 seconds above. Had we just stumbled upon some fundamental incompatibility between Go’s standard HTTP client and Puma? Not so fast.
A deeper dive into the ab documentation surfaced this option:
❯ ab -h
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
...
-k Use HTTP KeepAlive feature
That’s different than hey’s default of enabling keepalive by default. Could that be significant? We re-ran ab with -k:
❯ ab -k -c 10 -n 200 http://127.0.0.1:3000/fixed
This is ApacheBench, Version 2.3 <$Revision: 1913912 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 100 requests
Completed 200 requests
Finished 200 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 3000
Document Path: /fixed
Document Length: 3 bytes
Concurrency Level: 10
Time taken for tests: 8.564 seconds
Complete requests: 200
Failed requests: 0
Keep-Alive requests: 184
Total transferred: 39416 bytes
HTML transferred: 600 bytes
Requests per second: 23.35 [#/sec] (mean)
Time per request: 428.184 [ms] (mean)
Time per request: 42.818 [ms] (mean, across all concurrent requests)
Transfer rate: 4.49 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.5 0 6
Processing: 201 405 609.0 202 2453
Waiting: 201 405 609.0 202 2453
Total: 201 406 609.2 202 2453
Percentage of the requests served within a certain time (ms)
50% 202
66% 203
75% 203
80% 204
90% 2030
95% 2242
98% 2267
99% 2451
100% 2453 (longest request)
Now the output looked just like the hey output. Next, we ran hey with keepalives disabled:
Again, no long tail response times and the median values comparable to the first run with ab.
Even better, this neatly explained the performance difference between Router 2.0 and the legacy router. Router 2.0 adds support for HTTP keepalives by default, in line with HTTP/1.1 spec. In contrast, the legacy router closes connections to dynos after each request. Keepalives usually improve performance, reducing time spent in TCP operations for both the router and the dyno. Yet, the opposite was true for a dyno running Puma.
Note that we suggest reviewing this brief Puma architecture document if you’re unfamiliar with the framework and want to get the most out of this section. To skip the code review, you may fast-forward to The Solution.
This finding was enough of a smoking gun to send us deep into the the Puma server code, where we homed in on the process_client method. Let’s take a look at that code with a few details in mind:
Each Puma thread can only handle a single connection at at time. A client is a wrapper around a connection.
The handle_request method handles exactly 1 request. It returns false when the connection should be closed and true when it should be kept open. A client with keepalive enabled will end up in the true condition on line 470.
fast_check is only false once we’ve processed @max_fast_inline requests serially off the connection and when there are more connections waiting to be handled.
For some reason, even when the number of connections exceeds the max number of threads, @thread_pool.backlog > 0 is often times false.
Altogether, this means the below loop usually executes indefinitely until we’re able to bail out when handle_request returns false.
When does handle_request actually return false? That is also based on a bunch of conditional logic, the core of it is in the prepare_response method. Basically, if force_keep_alive is false, handle_request will return false. (This is not exactly true. It’s more complicated, but that’s not important for this discussion.)
The last thing to put the puzzle together: max_fast_inline defaults to 10. That means Puma will process at least 10 requests serially off a single connection before handing the connection back to the reactor class. Requests that may have come in a full second ago are just sitting in the queue, waiting for their turn. This directly explains our 10*200ms = 2 seconds of added response time for our longest requests!
We figured setting max_fast_inline=1 might fix this issue, and it does sometimes. However, under sufficient load, even with this setting, response times will climb. The problem is the other two OR’ed conditions circled in blue and red above. Sometimes the number of busy threads is less than the max and sometimes, there are no new connections to accept on the socket. However, these decisions are made at a point in time and the state of the server is constantly changing. They are subject to race conditions since other threads are concurrently accessing these variables and taking actions that modify their values.
After reviewing the Puma server code, we came to the conclusion that the simplest and safest way to bail out of processing requests serially would be to flat-out disable keepalives. Explicitly disabling keepalives in the Puma server means handing the client back to the reactor after each request. This is how we ensure requests are served in order.
Once confirming these results with the Heroku Ruby language owners, we opened a Github issue on the Puma project and a pull request to add an enable_keep_alives option to the Puma DSL. When set to false, keepalives are completely disabled. The option will be released soon, likely in Puma 6.5.0.
We then re-ran our load tests with enable_keep_alives disabled in Puma and Router 2.0 enabled on the app:
// config/puma.rb
...
enable_keep_alives false
The response times and throughput improved, as expected. Additionally, once disabling Router 2.0, the response times stayed the same:
Keeping connections alive reduces time spent in TCP operations. Under sufficient load and scale, avoiding this overhead cost can positively impact apps’ response times. Additionally, keepalives are the de facto standard in HTTP/1.1 and HTTP/2. Because of this, Heroku has chosen to move forward with keepalives as the default behavior for Router 2.0.
Through raising this issue on the Puma project, there has already been movement to fix the bad keepalive behavior in the Puma server. Heroku engineers remain active participants in discussions arounds these efforts and are committed to solving this problem. Once a full fix is available, customers will be able to upgrade their Puma versions and use keepalives safely, without risk of long response times.
In the meantime, we have provided another option for disabling keepalives when using Router 2.0. The following labs flag may be used in conjunction with Router 2.0 to disable keepalives between the router and your web dynos:
heroku labs:enable http-disable-keepalive-to-dyno -a my-app
You may find that your Puma app does not need keepalives disabled in order to perform well while using Router 2.0. We recommend testing and tuning other configuration options, so that your app can still benefit from persistent connections between the new router and your dyno:
Increase the number of threads. More threads means Puma is better able to handle concurrent connections.
Increase the number of workers. This is similar to increasing the number of threads.
Decrease the max_fast_inline number. This will limit the number of requests served serially off a connection before handling queued requests.
Our team also wanted to see if this same issue would present in other languages or frameworks. We ran load tests, injecting 200 milliseconds of server-side lag over the top languages and frameworks on the Heroku platform. Here are those results.
We were initially surprised by this keepalive behavior in the Puma server. Funny enough, we believe Heroku’s significance in the Puma/Rails world and the fact that the legacy router does not support keepalives may have been factors in this bug persisting for so long. Reports of it had popped up in the past (see Issue 3443, Issue 2625 and Issue 2331), but none of these prompted a fool-proof fix. Setting enable_keep_alives false does completely eliminate the problem, but this is not the default option. Now, Puma maintainers are taking a closer look at the problem and benchmarking potential fixes in a fork of the project. The intention is to fix the balancing of requests without closing TCP connections to the Puma server.
Our Heroku team is thrilled that we were able to contribute in this way and help move the Puma/Rails community forward. We’re also excited to release Router 2.0 as GA, unlocking new features like HTTP/2 and keepalives to your dynos. We encourage our users to try out this new router! For advice on how to go about that, see Tips & Tricks for Migrating to Router 2.0.
About a year ago, Honeycomb kicked off an internal experiment to structure how we do incident response. We looked at the usual severity-based approach (usually using a SEV scale), but decided to adopt an approach based on types, aiming to better play the role of quick definitions for multiple departments put together. This post is a short report on our experience doing it.
Problem statement
Incident priorities play the role of boundary object: a concept that is shared across various portions of an organization, but means different things and is used for distinct purposes by different people and departments.
The classic approach to incidents is to pick incident severity levels, often on a grid a bit like this:
SEV
Example Description
Example Response
1
Critical issue. Systems down. Impacts a large amount of or all customers. SLAs not being met. User data loss. Security issue where customer data is at risk. Organization survival at risk.
Public communications required. Executive teams involved. All hands on deck. Formal incident investigation and public reports expected.
2
Major issue. Severe impacts to a large number of customers. SLAs at risk. Incident response itself is affected. Product is unusable or inaccessible.
Public communications required. Internal status updates required. Formal incident command is activated. Subject matter experts across teams brought in. Formal incident investigation and public reports expected.
3
Minor issue. Some systems are not working properly, but most are. Some customers are impacted.
Public communications required. Internal status updates required. The team owning impacted systems are part of the response. Internal incident investigation expected.
4
Low impact. Informational notice. Performance may be degraded in some services. Some customers may see an impact.
Public communications may be useful if they can’t be handled directly to impacted customers. Mitigations can be worked on by on-call people if rollbacks aren’t adequate.
Some scales will vary in how many levels they have, on how automated their responses are, and in the criteria they include.
The challenge is that they offer a single linear scale that encompasses many elements:
Impact: number of services, performance and uptime implications, accessibility and usability criteria, contractual obligations.
Organizational factors: ownership definition, departments with different compliance requirements, budgets, and schedules.
Workload: types of communication, incident command structure, number of people involved, expected duration, investigations after the event, type of follow-up and action items (and urgency), types of procedures (such as “break-glass” situations).
Because severities are a single linear scale, they also create fuzzy boundaries and corner cases when elements ranging across severity levels are in a single incident:
What if a single customer has their data exposed or lost?
What if there’s performance degradation, but it’s system-wide and strategic customers are complaining and threatening to leave?
What if the impact is currently not visible, but if nothing is done within a day or two, it will be a SEV-1 incident?
These fuzzy boundaries are necessary when we are trying to trade off the complexity of the real situation with straightforward response mechanisms across an organization. However, they sure are messy.
Why it’s a mess
Each role offers a distinct perspective, asymmetric information, a varying set of priorities, and different tools—but is brought in line by a single event. The variety of stakeholders and people involved into a single scale like that means that it’s leveraged inconsistently across the organization:
An engineer who believes the impact to be wide but easily fixable may want to underplay the severity to avoid roping in external departments or activating machinery that will slow response while it ramps up and propagates to the organization. Responders may also try to delay formal response because they want to be very sure before activating it at full scale.
Someone who knows no customer-facing impact currently exists, but who needs org-wide support to resolve a looming threat may declare a higher severity incident to get the hands they believe they need.
Someone in a more customer-facing role may understand their pain more directly and argue in favor of a higher severity to properly communicate how serious the organization believes this is.
It isn’t necessarily problematic that we use a compressed set of terms to define incidents and their response. The issue is that we use a rather non-descriptive linear scale: a lower number means a more severe incident. The definitions are loose and depend on the stakeholder’s stance within the organization, but the responses are very real.
People will perceive the severity both as a norm to respond and as a tool, at the same time, and will also have different tolerances for disruption caused by the chosen severity, and the threshold between them. In case of ambiguous situations, some will default to noisier responses while others will wait for more validation before making that call—particularly if the severity of an incident is part of metrics and targets to be met or part of the organization for a given reporting period.
Experience shows that the outcome is accompanied by an ongoing tension between descriptive severity (based on the fuzzy impact and scope), prescriptive severity (what is the response we think we need), mixed in with time pressure, incomplete information, and objectives. The more we encompass in the severity mechanism, the trickier it is to navigate—and the longer the debates.
TL;DR: Response severity is different for every team
The response required by engineers may be more demanding for a non-customer impacting “ticking time bomb” situation or critical security vulnerability patch than it is for a higher-severity incident that requires a rollback.
For customer success teams, the breadth of impacted users and the magnitude (how unusable the product is) will define demand differently.
For incident commanders and managers, it is possible that broad involvement over long periods, at a high pace, will be more challenging than a one- or two-hour-long heavy session with a few subject matter experts.
The severity scales are linear, from lowest to most critical impact, but the responses for each type of stakeholder is not linear.
What we chose to do
This “tangling” effect is not necessarily avoidable by virtue of severity being a compromise across many stakeholders and viewpoints. I do not believe that approaches like “enforce the rules harder” or “make the guidelines even more complete” are effective. People do what they believe is useful, and that includes taking shortcuts and leveraging norms as tools.
If part of the challenge is that the severity scales are inherently linear and the response to incidents does not align with this linearity, then we may want to conclude that they are not a great pattern with which to orchestrate incident response. Instead, we may want to find a better pattern (even if not perfect either—it can never be) by ditching the severity and going for more descriptive types.
We decided, for example, to declare incidents that match any of the following terms:
Ambiguous: Not fully sure. Things look bad, but not fully broken (this is our default type).
Security: Security incidents have distinct workflows and compliance requirements.
Time bomb: Internal, but we need a lot of hands on deck if we don’t want it to get worse.
Isolated: One or few customers, over limited components.
Major: Key features or important customers are definitely impacted. Warrants a big response.
Being able to pick words lets people create workflows based on a description that correlates to surface, workload, and magnitude. Having too many words is likely to be as confusing as not having enough, so we want the number to be low enough. To pick adequate words, we went back into our history of incident response (not just public-facing incidents) to see if we could come up with archetypes that describe most of what we had to deal with—the expectation is that over time, we’ll need to adjust them based on newer or more frequent experiences.
The key point is that while these terms are ambiguous on purpose, they carry meaning. An “ambiguous” incident is hard to describe, but everyone has an idea what it means—especially when it’s bounded by “isolated” on the lower spectrum and “major” on the upper spectrum. Nobody’s necessarily mad at someone picking “ambiguous” as a value, which is often a useful property: the mess and uncertainty of the description is a feature of it all, not a bug. Clarity comes over time and people should understand that.
An “isolated” incident could very well be a major outage on a key feature that messes with a lot of customers, but that is fully understood to be a bad deploy, as much as it could be a thing that minorly impacts one customer but with a big financial incentive to keep them happy.
The ongoing outcome
We’ve also used these types as the foundation for workflows we’ve built with Jeli, the incident management and analysis software we’ve used for a few years now. Using these types and their custom workflows, security incidents come with private channels, and they automatically invite members of the security team into the incident channel, along with one person from platform leadership. Any public-facing (i.e., customer-impacting) type automatically invites representatives from our support team. Any non-internal type brings up incident response folks and appropriate leadership to help support the situation.
My point being, these descriptions carry meaning that goes further than a sliding scale, and that lets people subscribe or get involved based on what the term means rather than how bad it is (where “how bad” is defined differently for every department). We’ve managed to avoid creating more incident types than what we had.
Our goal is to create as clear of an incident as we can, as fast as possible. The definition helps pick a term based on what we see (or don’t know yet) more than anything, and has felt useful to most engineers we polled at the end of the experiment’s period.
A year later, we’re still using incident types as a mechanism. Unsurprisingly, most incidents fall into the ‘ambiguous’ category. This fits as designed, although our tooling doesn’t let us change types after an incident started. This has come up as the biggest hurdle of our current system, restricting how much flexibility and accuracy we’d get out of it.
We’re always on the lookout for more improvements (e.g., synchronizing PagerDuty schedules to Slack aliases makes automation useful). If you have insights on useful approaches, let us know in Pollinators, our Slack community.
Observability that helps you solve issues before they impact customers.
- Ambiguous: Not fully sure. Things look bad, but not fully broken (this is our default type). - Internal: Chaos experiments, rollouts, non-customer impacting things, tests. - Security: Security incidents have distinct workflows and compliance requirements. - Time bomb: Internal, but we need a lot of hands on deck if we don’t want it to get worse. - Isolated: One or few customers, over limited components. - Major: Key features or important customers are definitely impacted. Warrants a big response.
Wow using these types over SEVs would have save me and my team so much time in the past.
Imagine halving the resource costs of AI and what that could mean for the planet and the industry -- based on extreme estimates such savings could reduce the total US power usage by over 10% by 20301. At Intel we've been creating a new analyzer tool to help reduce AI costs called AI Flame Graphs: a visualization that shows an AI accelerator or GPU hardware profile along with the full software stack, based on my CPU flame graphs. Our first version is available to customers in the Intel Tiber AI Cloud as a preview for the Intel Data Center GPU Max Series (previously called Ponte Vecchio). Here is an example:
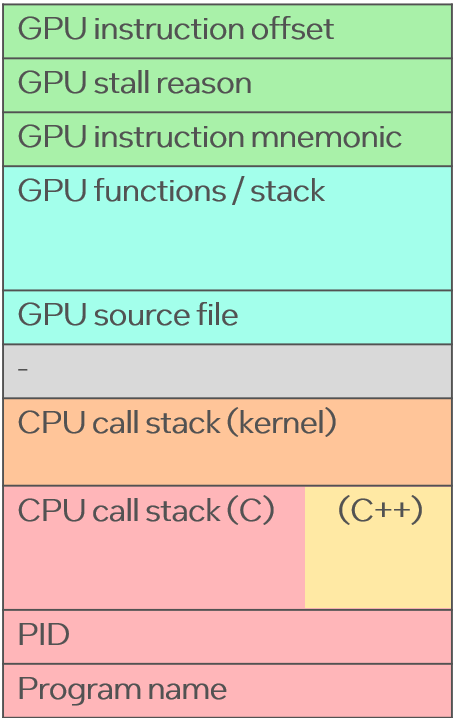
(Click for interactive SVG.) The green frames are the actual instructions running on the AI or GPU accelerator, aqua shows the source code for these functions, and red (C), yellow (C++), and orange (kernel) show the CPU code paths that initiated these AI/GPU programs. The gray "-" frames just help highlight the boundary between CPU and AI/GPU code. The x-axis is proportional to cost, so you look for the widest things and find ways to reduce them.
Layers
This flame graph shows a simple program for SYCL (a high-level C++ language for accelerators) that tests three implementations of matrix multiply, running them with the same input workload. The flame graph is dominated by the slowest implementation, multiply_basic(), which doesn't use any optimizations and consumes at 72% of stall samples and is shown as the widest tower. On the right are two thin towers for multiply_local_access() at 21% which replaces the accessor with a local variable, and multiply_local_access_and_tiling() at 6% which also adds matrix tiling. The towers are getting smaller as optimizations are added.
This flame graph profiler is a prototype based on Intel EU stall profiling for hardware profiling and eBPF for software instrumentation. It's designed to be easy and low-overhead, just like a CPU profiler. You should be able to generate a flame graph of an existing AI workload whenever you want, without having to restart anything or launch additional code via an interposer.
Instruction-offset Profiling
This is not the first project to build an AI profiler or even something called an AI Flame Graph, however, others I've seen focus on tracing CPU stacks and timing accelerator execution, but don't profile the instruction offsets running on the accelerator; or do profile them but via expensive binary instrumentation. I wanted to build AI flame graphs that work like CPU flame graphs: Easy to use, negligible cost, production safe, and shows everything. A daily tool for developers, with most of the visualization in the language of the developer: source code functions.
This has been an internal AI project at Intel for the past year. Intel was already investing in this space, building the EU stall profiler capability for the Intel Data Center GPU Max Series that provides an approximation of HW instruction sampling. I was lucky to have Dr. Matthew (Ben) Olson, an Intel AI engineer who has also worked on eBPF performance tooling (processwatch) as well as memory management research, join my team and do most of the development work. His background has helped us power through difficulties that seemed insurmountable. We've also recently been joined by Dr. Brandon Kammerdiener (coincidentally another graduate of the University of Tennessee, like Ben), who also has eBPF and memory internals experience, and has been helping us take on harder and harder workloads. And Gabriel Muñoz just joined today to help with releases. Now that our small team has shown that this is possible, we'll be joined by other teams at Intel to develop this further.
We could have built a harder-to-use and higher-overhead version months ago using Intel GTPin but for widespread adoption it needs minimal overhead and ease of use so that developers don't hesitate to use this daily and to add it to deployment pipelines.
What's a Flame Graph?
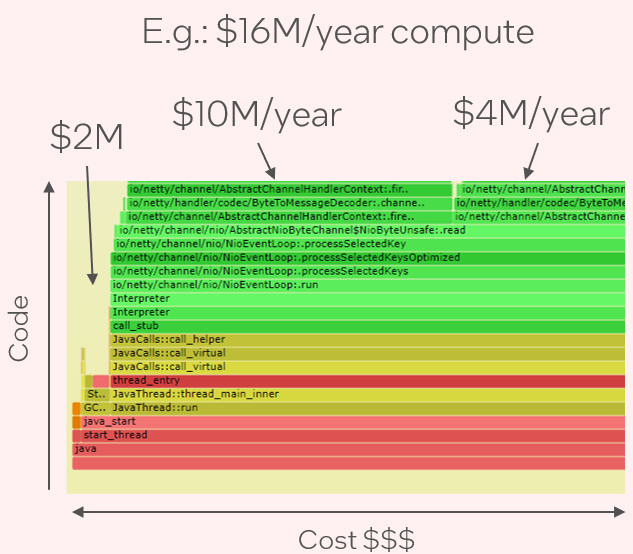
A flame graph is a visualization I invented in 2011 for showing sampled code stack traces. It has become the standard for CPU profiling and analysis, helping developers quickly find performance improvements and eliminate regressions. A CPU flame graph shows the "big picture" of running software, with x-axis proportional to CPU cost. The example picture on the right summarizes how easy it can be to go from compute costs to responsible code paths. Prior to flame graphs, it could take hours to understand a complex profile by reading through hundreds of pages of output. Now it takes seconds: all you have to do is look for the widest rectangles.
Flame graphs have had worldwide adoption. They have been the basis for five startups so far, have been adopted in over thirty performance analysis products, and have had over eighty implementations.
My first implementation of flame graphs took a few hours on a Wednesday night after work. The real effort has been in the decade since, where I worked with different profilers, runtimes, libraries, kernels, compilers, and hypervisors to get flame graphs working properly in different environments, including fixing stack walking and symbolization. Earlier this year I posted about the final missing piece: Helping distros enable frame pointers so that profiling works across standard system libraries.
Similar work is necessary for AI workloads: fixing stacks and symbols and getting profiling to work for different hardware, kernel drivers, user-mode drivers, frameworks, runtimes, languages, and models. A lot more work, too, as AI analysis has less maturity than CPU analysis.
Searching Samples
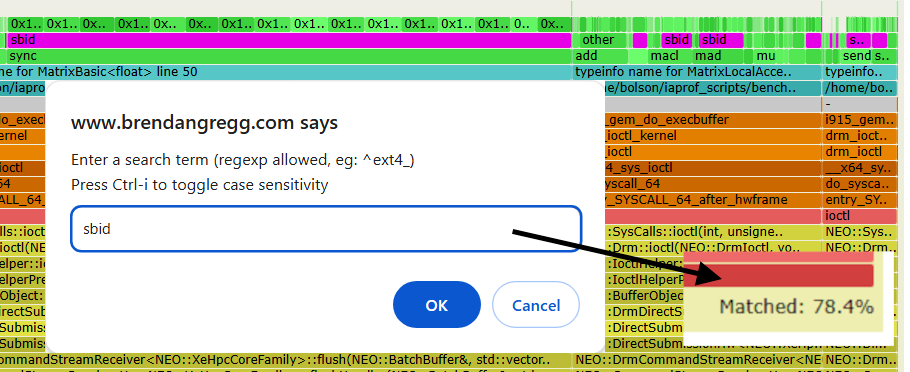
If you are new to flame graphs, it's worth highlighting the built-in search capability. In the earlier example, most of the stall samples are caused by sbid: software scoreboard dependency. As that may be a unique search term, you can run search (Ctrl-F, or click "Search") on "sbid" and it will highlight it in magenta:
Search also shows the total number of stack samples that contained sbid in the bottom right: 78.4%. You can search for any term in the flame graph: accelerator instructions, source paths, function names, etc., to quickly calculate the percentage of stacks where it is present (excluding vertical overlap) helping you prioritise performance work.
Note that the samples are EU stall-based, which means theoretical performance wins can take the percentages down to zero. This is different to timer-based samples as are typically used in CPU profiling. Stalls mean you better focus on the pain, the parts of the code that aren't making forward progress, but you aren't seeing resource usage by unstalled instructions. I'd like to supuport timer-based samples in the future as well, so we can have both views.
Who will use this?
At a recent golang conference, I asked the audience of 200+ to raise their hands if they were using CPU flame graphs. Almost every hand went up. I know of companies where flame graphs are a daily tool that developers use to understand and tune their code, reducing compute costs. This will become a daily tool for AI developers.
My employer will use this as well for evaluation analysis, to find areas to tune to beat competitors, as well as to better understand workload performance to aid design.
Why is AI profiling hard?
Consider CPU instruction profiling: This is easy when the program and symbol table are both in the file system and in a standardized file format (such as ELF) as is the case with native compiled code (C). CPU profiling gets hard for JIT-complied code, like Java, as instructions and symbols are dynamically generated and placed in main memory (the process heap) without following a universal standard. For such JITted code we use runtime-specific methods and agents to retrieve snapshots of the heap information, which is different for each runtime.
AI workloads also have different runtimes (and frameworks, languages, user-mode drivers, compilers, etc.) any of which can require special tinkering to get their CPU stacks and symbols to work. These CPU stacks are shown as the red, orange, and yellow frames in the AI Flame Graph. Some AI workloads are easy to get these frames working, some (like PyTorch) are a lot more work.
But the real challenge is instruction profiling of actual GPU and AI accelerator programs -- shown as the aqua and green frames -- and correctly associating them with the CPU stacks beneath them. Not only may these GPU and AI programs not exist in the file system, but they may not even exist in main memory! Even for running programs. Once execution begins, they may be deallocated from main memory and only exist in special accelerator memory, beyond the direct reach of OS profilers and debuggers. Or within reach, but only through a prohibitively high-overhead HW-specific debugger interface.
There's also no /proc representation for these programs either (I've been proposing building an equivalent) so there's no direct way to even tell what is running and what isn't, and all the other /proc details. Forget instruction profiling, even ps(1) and all the other process tools do not work.
It's been a mind-bending experience, revealing what gets taken for granted because it has existed in CPU land for decades: A process table. Process tools. Standard file formats. Programs that exist in the file system. Programs running from main memory. Debuggers. Profiliers. Core dumping. Disassembling. Single stepping. Static and dynamic instrumentation. Etc. For GPUs and AI, this is all far less mature. It can make the work exciting at times, when you think something is impossible and then find or devise a way.
Fortunately we have a head start as some things do exist. Depending on the runtime and kernel driver, there are debug interfaces where you can list running accelerator programs and other statistics, as used by tools like intel_gpu_top(1). You can kill -9 a GPU workload using intel_gpu_abrt(1). Some interfaces can even generate basic ELF files for the running accelerator programs that you can try to load in a debugger like gdb(1). And there is support for GPU/AI program disassembly, if you can get your hands on the binary. It feels to me like GPU/AI debugging, OS style, is about two years old. Better than zero, but still early on, and lots more ahead of us. A decade, at least.
What do AI developers think of this?
We've shown AI Flame Graphs to other AI developers at Intel and a common reaction is to be a bit puzzled, wondering what to do with it. AI developers think about their bit of code, but with AI Flame Graphs they can now see the entire stack for the first time, including the HW, and many layers they don't usually think about or don't know about. It basically looks like a pile of gibberish with their code only a small part of the flame graph.
CPU Flame Graph Implementations
This reaction is similar to people's first experiences with CPU flame graphs, which show parts of the system that developers and engineers typically don't work on, such as runtime internals, system libraries, and kernel internals. Flame graphs are great at highlighting the dozen or so functions that matter the most, so it becomes a problem of learning what those functions do across a few different code bases, which are typically open source. Understanding a dozen such functions can take a few hours or even a few days -- but if this leads to a 10% or 2x cost win, it is time well spent. And the next time the user looks at a flame graph, they start saying "I've seen that function before" and so on. You can get to the point where understanding the bulk of a CPU flame graph takes less than a minute: look for the widest tower, click to zoom, read the frames, done.
I'm encouraged by the success of CPU flame graphs, with over 80 implementations and countless real world case studies. Sometimes I'm browsing a performance issue I care about on github and hit page down and there's a CPU flame graph. They are everywhere.
I expect AI developers will also be able to understand AI Flame Graphs in less than a minute, but to start with people will be spending a day or more browsing code bases they didn't know were involved. Publishing case studies of found wins will also help people learn how to interpret them, and also help explain the value.
What about PyTorch?
Another common reaction we've had is that AI developers are using PyTorch, and initially we didn't support it as it meant walking Python stacks, which isn't trivial. But prior work has been done there (to support CPU profiling) and after a lot of tinkering we now have the first PyTorch AI Flame Graph:
PyTorch frames in pink
(Click for interactive SVG.) The PyTorch functions are at the bottom and are colored pink. This example runs oneDNN kernels that are JIT-generated, and don't have a source path so that layer just reads "jit". Getting all other the layers included was a real pain to get going, but an important milestone. We think if we can do PyTorch we can do anything.
In this flame graph, we show PyTorch running the Llama 2 7B model using the Intel Extensions for PyTorch (IPEX). This flame graph shows the origin of the GPU kernel execution all the way back to the Python source code shown in pink. Most samples are from a stack leading up to a gemm_kernel (matrix multiply) shown in aqua, which like the previous example has many stalls due to software scoreboarding.
There are two instructions here (0xa30 and 0xa90) that combined are 27% of the entire profile. I expect someone will ask: Can't we just click on instructions and have it bring up a dissassembly view with full source? Yes, that should be possible, but I can't answer how we're going to provide this yet. Another expected question I can't yet answer: Since there are now multiple products providing AI auto-tuning of CPU workloads using CPU flame graphs (including Intel Granulate) can't we have AI auto-tuning of AI workloads using AI Flame Graphs?
First Release: Sometimes hard and with moderate overhead
Getting AI Flame Graphs to work with some workloads is easy, but others are currently hard and cost moderate overhead. It's similar to CPU profiling, where some workloads and languages are easy to profile, whereas others need various things fixed. Some AI workloads use many software dependencies that need various tweaks and recompilation (e.g., enabling frame pointers so that stack walking works) making setup time consuming. PyTorch is especially difficult and can take over a week of OS work to be ready for AI Flame Graphs. We will work on getting these tweaks changed upstream in their respective repositories, something involving teams inside and outside of Intel, and is a process I'd expect to take at least a year. During that time AI workloads will gradually become easier to flame graph, and with lower-overhead as well.
I'm reminded of eBPF in the early days: You had to patch and recompile the kernel and LLVM and Clang, which could take multiple days if you hit errors. Since then all the eBPF dependency patches have been merged, and default settings changed, so that eBPF "just works." We'll get there with AI Flame Graphs too, but right now it's still those early days.
The changes necessary for AI Flame Graphs are really about improving debugging in general, and are a requirement for Fast by Friday: A vision where we can root-cause analyze anything in five days or less.
Availability
AI Flame Graphs will first become available on the Intel Tiber AI Cloud as a preview feature for the Intel Data Center GPU Max Series. If you are currently deployed there you can ask through the Intel service channel for early access. As for if or when it will support other hardware types, be in other Intel products, be officially launched, be open source, etc., these involve various other teams at Intel and they need to make their own announcements before I can discuss them here.
Conclusions
Finding performance improvements for AI data centers of just fractions of a percent can add up to planetary savings in electricity, water, and money. If AI flame graphs have the success that CPU flame graphs have had, I'd expect finding improvements of over 10% will be common, and 50% and higher will eventually be found*. But it won't be easy in these early days as there are still many software components to tweak and recompile, and software layers to learn about that are revealed in the AI flame graph.
In the years ahead I imagine others will build their own AI flame graphs that look the same as this one, and there may even be startups selling them, but if they use more difficult-to-use and higher-overhead technologies I fear they could turn companies off the idea of AI flame graphs altogether and prevent them from finding sorely needed wins. This is too important to do badly. AI flame graphs should be easy to use, cost negligible overhead, be production safe, and show everything. Intel has proven it's possible.
Disclaimer
* This is a personal blog post that makes personal predictions but not guarantees of possible performance improvements. Feel free to take any claim with a grain of salt, and feel free to wait for an official publication and public launch by Intel on this technology.
Thanks to everyone at Intel who have helped us make this happen. Markus Flierl has driven this project and made it a top priority, and Greg Lavender has expressed his support. Special thanks to Michael Cole, Matthew Roper, Luis Strano, Rodrigo Vivi, Joonas Lahtinen, Stanley Gambarin, Timothy Bauer, Brandon Yates, Maria Kraynyuk, Denis Samoylov, Krzysztof Raszknowski, Sanchit Jain, Po-Yu Chen, Felix Degrood, Piotr Rozenfeld, Andi Kleen, and all of the other coworkers that helped clear things up for us, and thanks in advance for everyone else who will be helping us in the months ahead.
My final thanks is to the companies and developers who do the actual hands-on work with flame graphs, collecting them, examining them, finding performance wins, and applying them. You are helping save the planet.





 Code snippet from
Code snippet from