Read Tokens, Please!

|
avid learner and developer[Ben.randomThoughts,GReader.shared,Delicious.public].tweet
|
About three months ago, I bought the Onyx BOOX 25.3” Mira Pro Color, an e-ink monitor for desktop use. I’ve used it as my primary monitor since, and I’ve had a lot of questions about it. This is my experience report, from the perspective of a working, still mostly typing, programmer.
This is not a sponsored post, and it is not a product review. I wrote a very similar post about the Daylight DC-1 last year.

As explained in last year’s post, the reason I persist with these monitors is because it makes me energetic and happy. Sunlight, direct or indirect, helps me stay clear and focused during my workday. I find spaces illuminated by natural light beautiful and inspiring.
I’m not going to recommend that you buy one of these devices. They’re expensive, about $2000, and the experience is quite different from LCD. Even if this looks cool, it seems to me very possible that most people would not like it in practice. With that said, I am happy with it, and I’ll probably keep investing in these tools as they get even better with time.
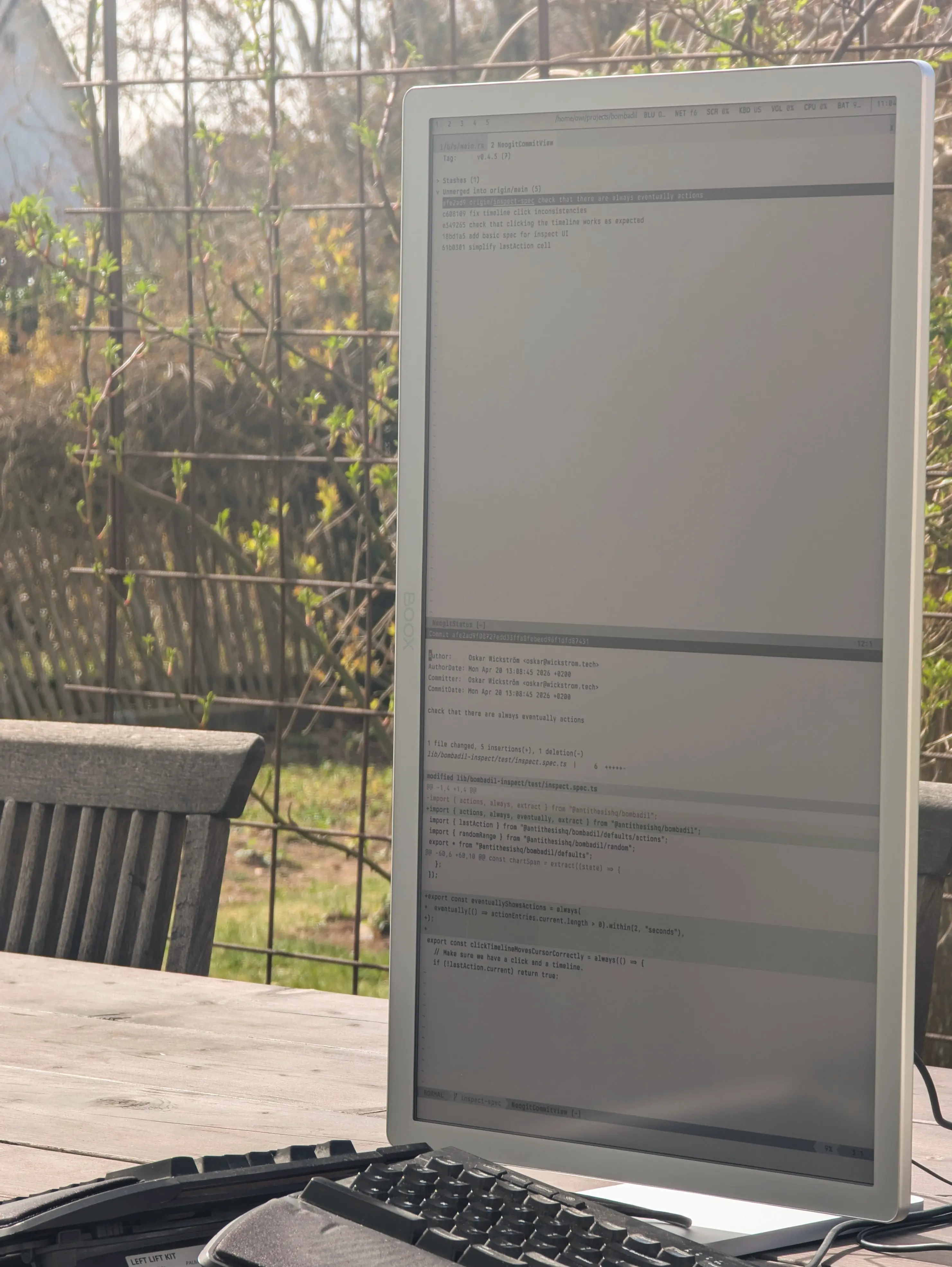
Using the Mira Pro as a primary monitor is a continuation of the experiments with my e-ink tablets and Termux as coding environments. But now, with far fewer compromises. I’m running my regular NixOS environment on my work laptop. No SSH and tmux needed, no Android terminal emulator to customize.
What I have done, though, is spent quite some time on making my system more suited for this monitor. The Mira Pro does not work well with dark themes. In fact, it only works well with high contrast light themes.
Luckily, I’m bent towards minimalism, so I already used near-monochrome themes, relying more on typographic syntax highlighting rather than coloring. I now have custom themes for Neovim, Zed, and Ghostty with a few vivid colors for things like selection, comments, and constants. Otherwise it’s largely black on white.
It’s trickier with other applications. In Firefox, I’ve started using the high contrast setting. That works pretty much like an inverse of DarkReader. I now run Spotify in the browser in order to avoid its dark theme.
The monitor has a clunky menu system with which you can change rendering modes; things like contrast and speed. I found an open-source reverse-engineered NodeJS package that I use with Hyprland keybindings to easily change rendering modes and manually refresh. No need for the built-in menu.
In practice I use two modes:
- Reading:
-
This mode renders colors most vividly and text sharply, but typing with it is agony. I use it when reading text documents, web pages, or code diffs.
- Writing:
-
This is by far the most commonly used mode, which compromises colors and sharpness for way better latency. I use this for everything in the terminal, chat, general web browsing, and probably most other things not covered by the reading mode.
See the following photos for a close-up comparison:
What about latency? Here’s the two short clips of me typing with the reading and writing modes:
Ghosting? In my writing mode it’s minimal. It really doesn’t bother me.
About the color panel: I don’t like it very much to be honest. It was the only version of the Mira Pro available from the Swedish retailer at the time, so I went with it. I think I would’ve been happier with a monochrome panel, because the coloring technology makes it considerably darker.
Here’s a comparison between the Palma 2 Pro (using a similar but smaller Kaleido color panel) and my old Tab Ultra (with a monochrome panel):

Unless the room has great diffuse lighting, natural or otherwise, the color panel does require some backlight. In direct sunlight or outdoors it works without. I might spend more time optimizing the lighting in my office to make this work during the winter months.
So, what’s to make of it? Personally, I enjoy using this monitor a lot, even if it’s not perfect. Should you buy an expensive 25” e-ink monitor? I cannot say. But if you do, let me know how it works out.
My custom themes and keybindings can be found here.
Fifteen years ago, when some colleagues and I were building Heroku’s V3 API, we set an ambitious goal: the public API should be powerful enough to run our own dashboard. No private endpoints, no escape hatches.
It was a stretch, but it worked. A new version of the company’s dashboard shipped on V3, and an unaffiliated developer who we’d never met before built Heroku’s first iOS app on it, without a single feature request sent our way.
The first wave
Our dashboard-on-public-APIs-only seems needlessly idealistic nowadays, but it was an objective born of the time. The year was 2011, and the optimism around the power of APIs was palpable. A new world was opening up. One of openness, interconnectivity, unbounded possibility.
And we weren’t the only ones thinking that way:
Only a year before (2010) Facebook released its original Open Graph API, providing immensely powerful insights into its platform data.
Twitter’s API at the time was almost completely open. You didn’t even need an OAuth token — just authenticate on API endpoints with your username/password and get access to just about anything.
GitHub was doing really impressive API design work, providing an expansive, feature-complete API with access to anything developers could need, and playing with forward-thinking ideas like hypermedia APIs/HATEOAS.
You can still find traces of this bygone era, standing like some cyclopean ruins from a previous age. Hit the root GitHub API and you’ll find an artifact over a decade old — a list of links that were intended to be followed as hypermedia:
$ curl https://api.github.com | jq
{
"current_user_url": "https://api.github.com/user",
"current_user_authorizations_html_url": "https://github.com/settings/connections/applications{/client_id}",
"authorizations_url": "https://api.github.com/authorizations",
"code_search_url": "https://api.github.com/search/code?q={query}{&page,per_page,sort,order}",
"commit_search_url": "https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}",
"emails_url": "https://api.github.com/user/emails",
"emojis_url": "https://api.github.com/emojis",
"events_url": "https://api.github.com/events",
...
This wasn’t a pre-planned, stack-ranked feature that a product team spent half a year putting together. It was one or two early engineers who got really excited about an API idea, and shipped it, probably without even asking for permission.
Part of the push for open APIs was simple good will towards the rest of the world. The engineers building them were brought up in the earliest days of the internet, steeped in its original counterculture, and had an innate bias for radical openness.
There was also a feeling from the companies involved that the APIs would be beneficial for their bottom lines. Users and third parties would use APIs to supplement the core product with add-ons and extensions that’d drive growth and increase product retention and satisfaction.
Sites like the now defunct ProgrammableWeb popped up to discuss and catalog the newly appearing APIs, and the “programmable web” wasn’t only a website, it was a principle.
In the near future, all platforms would be API-first, providing full programmatic access and opening a new wave of interoperability across the web that’d let any service talk to any other service and massively accelerate the scope and reach of the internet. APIs would help expand everything from freedom to communication to commerce. An overwhelming force for good in the world.
API winter
Of course, it didn’t last. The programmable web went through a phase of expansion, reached its maximum extent, and began to contract.
Twitter’s famous API, which used to be an API tinkerer’s dream, leveled off and began to dip as the company struggled to find ways to generate revenue. New features no longer got first-class API treatment. Access to the firehose was closed. Third-party Twitter clients were restricted and eventually locked out.
The power of Facebook’s Graph API was hugely constricted post-Cambridge Analytica where a single rogue app was able to suck up data on millions of users and put it up for sale. Strict app review procedures were implemented. The API went from open access to a walled garden.
Even more extreme, Instagram’s previously public API was deprecated totally. Realizing they had a real money maker on their hands, they saw no reason to share ad revenue with anyone else. Use Instagram through the first-party app or not at all.
Even APIs like GitHub’s that stayed quite open had to crack down to a degree. Endpoints became authenticated by necessity and aggressive rate limiting was put in to curb abuse and reduce operational toil. And even when APIs were still largely accessible, using them to build a full-scale third-party app became more difficult as limiters flattened heavy (even if legitimate) use.
The rationale for why APIs were being declawed or disappearing completely varied—abuse, monetization pressure, competitive risk, privacy, etc.—but the pattern was clear. Walls were going up across the world.
APIs didn’t disappear, but it was a cold winter for them. The expectation of an API became more limited to developer-focused platforms whose users paid them — Stripe, Twilio, Slack, etc. When new consumer products appeared on the market (e.g. TikTok), no one expected them to have much in the way of an API.
The coming second wave
For many years this was the status quo. If you were using Twitter, you’d use it from Twitter.com. Facebook, from Facebook.com. Instagram or TikTok, from their respective iOS/Android apps. Developer products like GitHub and Stripe continued strong, but elsewhere, APIs weren’t enough of a competitive advantage for anyone who didn’t have one to suffer.
But around mid-2025, the world changed. The last half year especially has been distinguished by the rise of indescribably powerful LLMs, which now dominate discourse as the most useful new tool in a generation.
They’re already useful enough as incredible trivia machines or code generators, but they really start to shine when they integrate with things. It’s pretty neat having one generate a valid Kubernetes configuration for your new app, but it’s really neat watching it provision an EKS cluster via awscli and send out its first production deploy on your behalf.
Suddenly, an API is no longer liability, but a major saleable vector to give users what they want: a way into the services they use and pay for so that an agent can carry out work on their behalf. Especially given a field of relatively undifferentiated products, in the near future the availability of an API might just be the crucial deciding factor that leads to one choice winning the field.
Picking my future bank
Let’s think about banks. I have a couple bank accounts, each offering a standard set of features largely unchanged since the 60s. If I call them, they’ll send me some checks. I can request a transfer between two internal accounts and they will transfer the money … in 1-5 business days. Nowadays, they even offer ultra-modern features (from 2010) like gasp, MFA, just as long as it’s through a provider that’s paid them off (Symantec VIP). Suffice it to say, they’re comfortable in the status quo. My banks do not have good APIs.
So far this has worked out okay for them. People aren’t known to migrate banks often, and even if they did, regulatory moats make new incumbents rare.
But in the modern age, can it last? When I want to move $100 from one bank to another, my banks put me through a humiliating ritual of logging into both accounts, and bypassing multiple security checks and captchas before I can perform any operation. All this despite me having just logged into both accounts from this exact location and biometrically-secured computer the day before.
The world I want is to instruct an LLM: “move $100 from Wells Fargo checking to Charles Schwab brokerage” and it will just happen. And to be fair, LLMs are already so absurdly good at reverse engineering things that this might already work today. But you know what’d work better? If both banks shipped with APIs, LLM-friendly usage instructions (through MCP or the like), and a strong auth layer to give me confidence that the whole process is secure.
If I were choosing a bank today, some considerations would be the same as they’ve always been—competent security, free checking, no foreign transaction fees—but I’d also futureproof the choice by picking one that’s established technical bona fides by providing an API. Even if I’m not quite ready to trust my banking credentials to an agent quite yet, I assume that this day is coming.
Ubiquitous again
Now apply the same principle to every service you use during the course of a week, or ever:
Online marketplaces: Robot, schedule my normal Amazon Fresh order for the first available slot tomorrow morning.
Office co-working: Robot, book me a desk at Embarcadero Center today.
Ski resorts: Robot, buy me a day pass for tomorrow and load it to my resort card. Confirm the price with me first.
Restaurants: Robot, put in my usual lunch order at Musubi Kai. Get me the unadon!
Where wouldn’t you want an API?
Forecasting the future is infamously hazardous, but based on the adoption patterns of myself and the people around me, I expect the demand to interact with services through LLMs is going to be overwhelming, and services aiming to provide a good product experience or which face competitive pressure (i.e. someone else could provide that experience instead) will offer APIs.
I used to wish that we’d gone down an alternative branch of web technology and adopted a protocol like Gopher) so we’d have a more standardized web experience instead of every product you use producing its own unique UX, most bad. I think we will see more standardization, just not in the form I expected. The convention of the future will be human language, fed into what looks a lot like a terminal, and fulfilled via API.
On behalf of people
Notably, this is different than the first wave of APIs that I described above. Instead of APIs being to offer infinitely flexible access for inter-service communication, scrape data, or build apps on top of someone else’s platform, their primary use will be to fulfill requests on behalf of a primary user. Exactly like what they’d be doing through a first-party app, but in a programmatic way.


It may seem like a subtle distinction, but there are considerable differences. The second model better incentivizes APIs to exist:
APIs aren’t for building a product that aims to displace the offerings of the underlying platform, but rather for giving users an alternative way to access it.
Security models are simplified because they’re the same ones used by the product itself. Users have the same visibility that they’d have through a first-party app, and no more.
Aiming to support access patterns for a single person, platforms can rate limit much more aggressively to curb expenses and operational problems associated with offering an API.
APIs should aim to provide a little more leeway than they would for a human, but only nominally so. An agent acting on my behalf should be able to occasionally poll LinkedIn for old colleagues that I should be reconnecting with and send them connect requests, but if someone’s set up their ClawBot to scrape the entire social graph on their behalf, platforms should feel more than free to throttle the hell out of them and give them a strike towards a permanent ban.
Slack’s rate limits are a good example of this, supporting numbers like 50 channel or 100 profile reads per minute. You can’t build a multi-user app with 50 channel reads per minute, but it’s plenty for a single user to access their own account.
Limits of the model
While can expect many products and services to offer APIs for good agentic interoperability, it won’t be forthcoming everywhere.
Don’t expect much out of Instagram, TikTok, or other platforms that power themselves with ads. Neither from monopolies that won’t feel any serious pressure to change — you won’t be reliably paying your Xfinity bill via agent anytime soon.
Hints of the future, today
In this section I figured I’d call out a few services that are already pulling this future forward:
- As I was in the middle of writing this essay, I got a note from Basecamp that they’d revamped themselves for LLM accessibility, including new API, new CLI, and bundled skill to instruct agents on their use.
API spring
Fifteen years ago, us API maximalists thought that APIs were going to eat the world, ushering in a new paradigm of interoperability that would vastly expand our capabilities as users, and even change the world for the better.
What we got instead was an API winter. As useful as APIs were in some situations, that usefulness was outweighed by concerns around revenue, privacy, and abuse.
But as scary of a thought as it was that this might be the end, it wasn’t. We’re at the beginning of a new spring of APIs that’ll appear to support use by agents acting on behalf of people. As this mode of operation gets more popular, expect the availability of an API to be a competitive edge that differentiates a service from its competitors. The result will be a global proliferation of APIs and expanding product capability like never before seen.
If you haven’t been living under a rock, you will have noticed this week that a project of my friend Peter went viral on the internet. It went by many names. The most recent one is OpenClaw but in the news you might have encountered it as ClawdBot or MoltBot depending on when you read about it. It is an agent connected to a communication channel of your choice that just runs code.
What you might be less familiar with is that what’s under the hood of OpenClaw is a little coding agent called Pi. And Pi happens to be, at this point, the coding agent that I use almost exclusively. Over the last few weeks I became more and more of a shill for the little agent. After I gave a talk on this recently, I realized that I did not actually write about Pi on this blog yet, so I feel like I might want to give some context on why I’m obsessed with it, and how it relates to OpenClaw.
Pi is written by Mario Zechner and unlike Peter, who aims for “sci-fi with a touch of madness,” 1 Mario is very grounded. Despite the differences in approach, both OpenClaw and Pi follow the same idea: LLMs are really good at writing and running code, so embrace this. In some ways I think that’s not an accident because Peter got me and Mario hooked on this idea, and agents last year.
What is Pi?
So Pi is a coding agent. And there are many coding agents. Really, I think you can pick effectively anyone off the shelf at this point and you will be able to experience what it’s like to do agentic programming. In reviews on this blog I’ve positively talked about AMP and one of the reasons I resonated so much with AMP is that it really felt like it was a product built by people who got both addicted to agentic programming but also had tried a few different things to see which ones work and not just to build a fancy UI around it.
Pi is interesting to me because of two main reasons:
- First of all, it has a tiny core. It has the shortest system prompt of any agent that I’m aware of and it only has four tools: Read, Write, Edit, Bash.
- The second thing is that it makes up for its tiny core by providing an extension system that also allows extensions to persist state into sessions, which is incredibly powerful.
And a little bonus: Pi itself is written like excellent software. It doesn’t flicker, it doesn’t consume a lot of memory, it doesn’t randomly break, it is very reliable and it is written by someone who takes great care of what goes into the software.
Pi also is a collection of little components that you can build your own agent on top. That’s how OpenClaw is built, and that’s also how I built my own little Telegram bot and how Mario built his mom. If you want to build your own agent, connected to something, Pi when pointed to itself and mom, will conjure one up for you.
What’s Not In Pi
And in order to understand what’s in Pi, it’s even more important to understand what’s not in Pi, why it’s not in Pi and more importantly: why it won’t be in Pi. The most obvious omission is support for MCP. There is no MCP support in it. While you could build an extension for it, you can also do what OpenClaw does to support MCP which is to use mcporter. mcporter exposes MCP calls via a CLI interface or TypeScript bindings and maybe your agent can do something with it. Or not, I don’t know :)
And this is not a lazy omission. This is from the philosophy of how Pi works. Pi’s entire idea is that if you want the agent to do something that it doesn’t do yet, you don’t go and download an extension or a skill or something like this. You ask the agent to extend itself. It celebrates the idea of code writing and running code.
That’s not to say that you cannot download extensions. It is very much supported. But instead of necessarily encouraging you to download someone else’s extension, you can also point your agent to an already existing extension, say like, build it like the thing you see over there, but make these changes to it that you like.
Agents Built for Agents Building Agents
When you look at what Pi and by extension OpenClaw are doing, there is an example of software that is malleable like clay. And this sets certain requirements for the underlying architecture of it that are actually in many ways setting certain constraints on the system that really need to go into the core design.
So for instance, Pi’s underlying AI SDK is written so that a session can really contain many different messages from many different model providers. It recognizes that the portability of sessions is somewhat limited between model providers and so it doesn’t lean in too much into any model-provider-specific feature set that cannot be transferred to another.
The second is that in addition to the model messages it maintains custom messages in the session files which can be used by extensions to store state or by the system itself to maintain information that either not at all is sent to the AI or only parts of it.
Because this system exists and extension state can also be persisted to disk, it has built-in hot reloading so that the agent can write code, reload, test it and go in a loop until your extension actually is functional. It also ships with documentation and examples that the agent itself can use to extend itself. Even better: sessions in Pi are trees. You can branch and navigate within a session which opens up all kinds of interesting opportunities such as enabling workflows for making a side-quest to fix a broken agent tool without wasting context in the main session. After the tool is fixed, I can rewind the session back to earlier and Pi summarizes what has happened on the other branch.
This all matters because for instance if you consider how MCP works, on most model providers, tools for MCP, like any tool for the LLM, need to be loaded into the system context or the tool section thereof on session start. That makes it very hard to impossible to fully reload what tools can do without trashing the complete cache or confusing the AI about how prior invocations work differently.
Tools Outside The Context
An extension in Pi can register a tool to be available to the LLM to call and every once in a while I find this useful. For instance, despite my criticism of how Beads is implemented, I do think that giving an agent access to a to-do list is a very useful thing. And I do use an agent-specific issue tracker that works locally that I had my agent build itself. And because I wanted the agent to also manage to-dos, in this particular case I decided to give it a tool rather than a CLI. It felt appropriate for the scope of the problem and it is currently the only additional tool that I’m loading into my context.
But for the most part all of what I’m adding to my agent are either skills or TUI extensions to make working with the agent more enjoyable for me. Beyond slash commands, Pi extensions can render custom TUI components directly in the terminal: spinners, progress bars, interactive file pickers, data tables, preview panes. The TUI is flexible enough that Mario proved you can run Doom in it. Not practical, but if you can run Doom, you can certainly build a useful dashboard or debugging interface.
I want to highlight some of my extensions to give you an idea of what’s possible. While you can use them unmodified, the whole idea really is that you point your agent to one and remix it to your heart’s content.
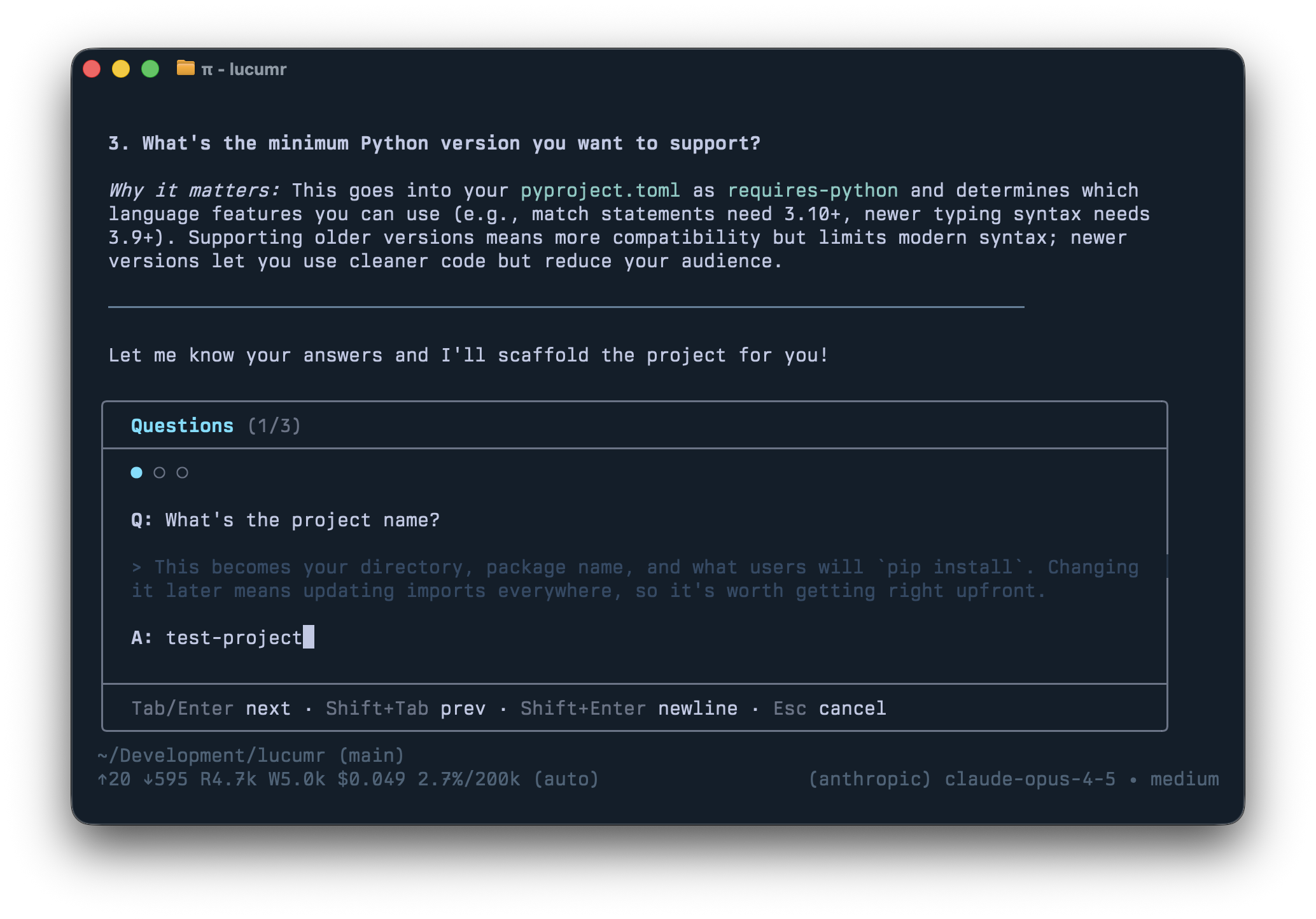
/answer
I don’t use plan mode. I encourage the agent to ask questions and there’s a productive back and forth. But I don’t like structured question dialogs that happen if you give the agent a question tool. I prefer the agent’s natural prose with explanations and diagrams interspersed.
The problem: answering questions inline gets messy. So /answer reads the
agent’s last response, extracts all the questions, and reformats them into a
nice input box.
/todos
Even though I criticize Beads for its
implementation, giving an agent a to-do list is genuinely useful. The /todos
command brings up all items stored in .pi/todos as markdown files. Both the
agent and I can manipulate them, and sessions can claim tasks to mark them as in
progress.
/review
As more code is written by agents, it makes little sense to throw unfinished work at humans before an agent has reviewed it first. Because Pi sessions are trees, I can branch into a fresh review context, get findings, then bring fixes back to the main session.
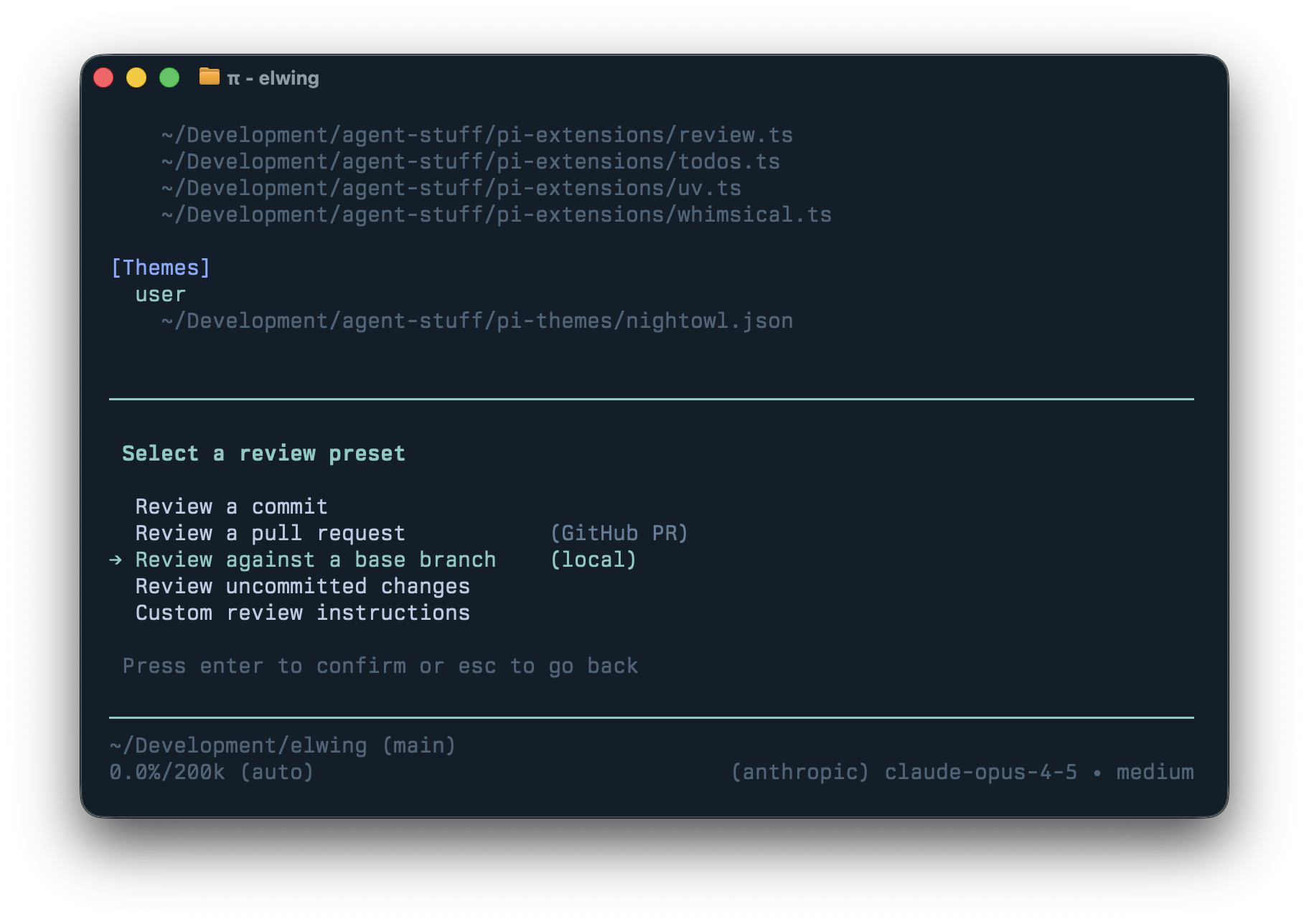
The UI is modeled after Codex which provides easy to review commits, diffs, uncommitted changes, or remote PRs. The prompt pays attention to things I care about so I get the call-outs I want (eg: I ask it to call out newly added dependencies.)
/control
An extension I experiment with but don’t actively use. It lets one Pi agent send prompts to another. It is a simple multi-agent system without complex orchestration which is useful for experimentation.
/files
Lists all files changed or referenced in the session. You can reveal them in
Finder, diff in VS Code, quick-look them, or reference them in your prompt.
shift+ctrl+r quick-looks the most recently mentioned file which is handy when
the agent produces a PDF.
Others have built extensions too: Nico’s subagent extension and interactive-shell which lets Pi autonomously run interactive CLIs in an observable TUI overlay.
Software Building Software
These are all just ideas of what you can do with your agent. The point of it mostly is that none of this was written by me, it was created by the agent to my specifications. I told Pi to make an extension and it did. There is no MCP, there are no community skills, nothing. Don’t get me wrong, I use tons of skills. But they are hand-crafted by my clanker and not downloaded from anywhere. For instance I fully replaced all my CLIs or MCPs for browser automation with a skill that just uses CDP. Not because the alternatives don’t work, or are bad, but because this is just easy and natural. The agent maintains its own functionality.
My agent has quite a few
skills and crucially
I throw skills away if I don’t need them. I for instance gave it a skill to
read Pi sessions that other engineers shared, which helps with code review. Or
I have a skill to help the agent craft the commit messages and commit behavior I
want, and how to update changelogs. These were originally slash commands, but
I’m currently migrating them to skills to see if this works equally well. I
also have a skill that hopefully helps Pi use uv rather than pip, but I also
added a custom extension to intercept calls to pip and python to redirect
them to uv instead.
Part of the fascination that working with a minimal agent like Pi gave me is that it makes you live that idea of using software that builds more software. That taken to the extreme is when you remove the UI and output and connect it to your chat. That’s what OpenClaw does and given its tremendous growth, I really feel more and more that this is going to become our future in one way or another.
Article URL: https://mariozechner.at/posts/2025-11-30-pi-coding-agent/
Comments URL: https://news.ycombinator.com/item?id=46844822
Points: 195
# Comments: 79
My coworkers really like AI-powered code review tools and it seems that every time I make a pull request in one of their repos I learn about yet another AI code review SaaS product. Given that there are so many of them, I decided to see how easy it would be to develop my own AI-powered code review bot that targets GitHub repositories. I managed to hack out the core of it in a single afternoon using a model that runs on my desk. I've ended up with a little tool I call reviewbot that takes GitHub pull request information and submits code reviews in response.
reviewbot is powered by a DGX Spark, llama.cpp, and OpenAI's GPT-OSS 120b. The AI model runs on my desk with a machine that pulls less power doing AI inference than my gaming tower pulls running fairly lightweight 3D games. In testing I've found that nearly all runs of reviewbot take less than two minutes, even at a rate of only 60 tokens per second generated by the DGX Spark.
reviewbot is about 350 lines of Go that just feeds pull request information into the context window of the model and provides a few tools for actions like "leave pull request review" and "read contents of file". I'm considering adding other actions like "read messages in thread" or "read contents of issue", but I haven't needed them yet.
To make my life easier, I distribute it as a Docker image that gets run in GitHub Actions whenever a pull review comment includes the magic phrase /reviewbot.
The main reason I made reviewbot is that I couldn't find anything like it that let you specify the combination of:
- Your own AI model name
- Your own AI model provider URL
- Your own AI model provider API token
I'm fairly sure that there are thousands of similar AI-powered tools on the market that I can't find because Google is a broken tool, but this one is mine.
How it works
When reviewbot reviews a pull request, it assembles an AI model prompt like this:
Pull request info:
<pr>
<title>Pull request title</title>
<author>GitHub username of pull request author</author>
<body>
Text body of the pull request
</body>
</pr>
Commits:
<commits>
<commit>
<author>Xe</author>
<message>
chore: minor formatting and cleanup fixes
- Format .mcp.json with prettier
- Minor whitespace cleanup
Assisted-by: GLM 4.7 via Claude Code
Reviewbot-request: yes
Signed-off-by: Xe Iaso <me@xeiaso.net>
</message>
</commit>
</commits>
Files changed:
<files>
<file>
<name>.mcp.json</name>
<status>modified</status>
<patch>
@@ -3,11 +3,8 @@
"python": {
"type": "stdio",
"command": "go",
- "args": [
- "run",
- "./cmd/python-wasm-mcp"
- ],
+ "args": ["run", "./cmd/python-wasm-mcp"],
"env": {}
}
}
-}
\ No newline at end of file
+}
</patch>
</file>
</files>
Agent information:
<agentInfo>
[contents of AGENTS.d in the repository]
</agentInfo>
The AI model can return one of three results:
- Definite approval via the
submit_reviewtool that approves the changes with a summary of the changes made to the code. - Definite rejection via the
submit_reviewtool that rejects the changes with a summary of the reason why they're being rejected. - Comments without approving or rejecting the code.
The core of reviewbot is the "AI agent loop", or a loop that works like this:
- Collect information to feed into the AI model
- Submit information to AI model
- If the AI model runs the
submit_reviewtool, publish the results and exit. - If the AI model runs any other tool, collect the information it's requesting and add it to the list of things to submit to the AI model in the next loop.
- If the AI model just returns text at any point, treat that as a noncommittal comment about the changes.
Don't use reviewbot
reviewbot is a hack that probably works well enough for me. It has a number of limitations including but not limited to:
- It does not work with closed source repositories due to the gitfs library not supporting cloning repositories that require authentication. Could probably fix that with some elbow grease if I'm paid enough to do so.
- A fair number of test invocations had the agent rely on unpopulated fields from the GitHub API, which caused crashes. I am certain that I will only find more such examples and need to issue patches for them.
- reviewbot is like 300 lines of Go hacked up by hand in an afternoon. If you really need something like this, you can likely write one yourself with little effort.
Frequently asked questions
When such an innovation as reviewbot comes to pass, people naturally have questions. In order to give you the best reading experience, I asked my friends, patrons, and loved ones for their questions about reviewbot. Here are some answers that may or may not help:
Does the world really need another AI agent?
Probably not! This is something I made out of curiosity, not something I made for you to actually use. It was a lot easier to make than I expected and is surprisingly useful for how little effort was put into it.
Is there a theme of FAQ questions that you're looking for?
Nope. Pure chaos. Let it all happen in a glorious way.
Where do we go when we die?
How the fuck should I know? I don't even know if chairs exist.
Has anyone ever really been far even as decided to use even go want to do look more like?
At least half as much I have wanted to use go wish for that. It's just common sense, really.
If you have a pile of sand and take away one grain at a time, when does it stop being a pile?
When the wind can blow all the sand away.
How often does it require oatmeal?
Three times daily or the netherbeast will emerge and doom all of society. We don't really want that to happen so we make sure to feed reviewbot its oatmeal.
How many pancakes does it take to shingle a dog house?
At least twelve. Not sure because I ran out of pancakes.
Will this crush my enemies, have them fall at my feet, their horses and goods taken?
Only if you add that functionality in a pull request. reviewbot can do anything as long as its code is extended to do that thing.
Why should I use reviewbot?
Frankly, you shouldn't.
Funny. But also shows how simple it can be to create an PR review agent.
Canada

Next Page of Stories